Experiences with Strangler fig approach using Change Data Capture
Business Context
Client is an e-commerce platform shipping to 130+countries around the globe. Their order fulfillment for all the countries was happening out of their local warehouse in western asia. Since most of their revenues come from the European Union (EU) region, they chose to set up a new warehouse within the EU.
Problems that needs to be solved
- The new warehouse will be managed by a 3rd party logistics (3PL) company. The 3PL will likely have a view on stocks that are managed in their warehouse. They need a source of truth for their stock data across the warehouses.
- There is no dimension of warehouse in the current system. The stock entry is defaulted to their only warehouse. The current system also lacked the details for stock being non-sellable (like In Transit, Damaged, Missing etc).
- Current legacy system was hard to change. Hence it was decided to move the stock domain into a new system. It will be done gradually, meaning for a considerable time we will need both the systems to co-exist.
Design Decision
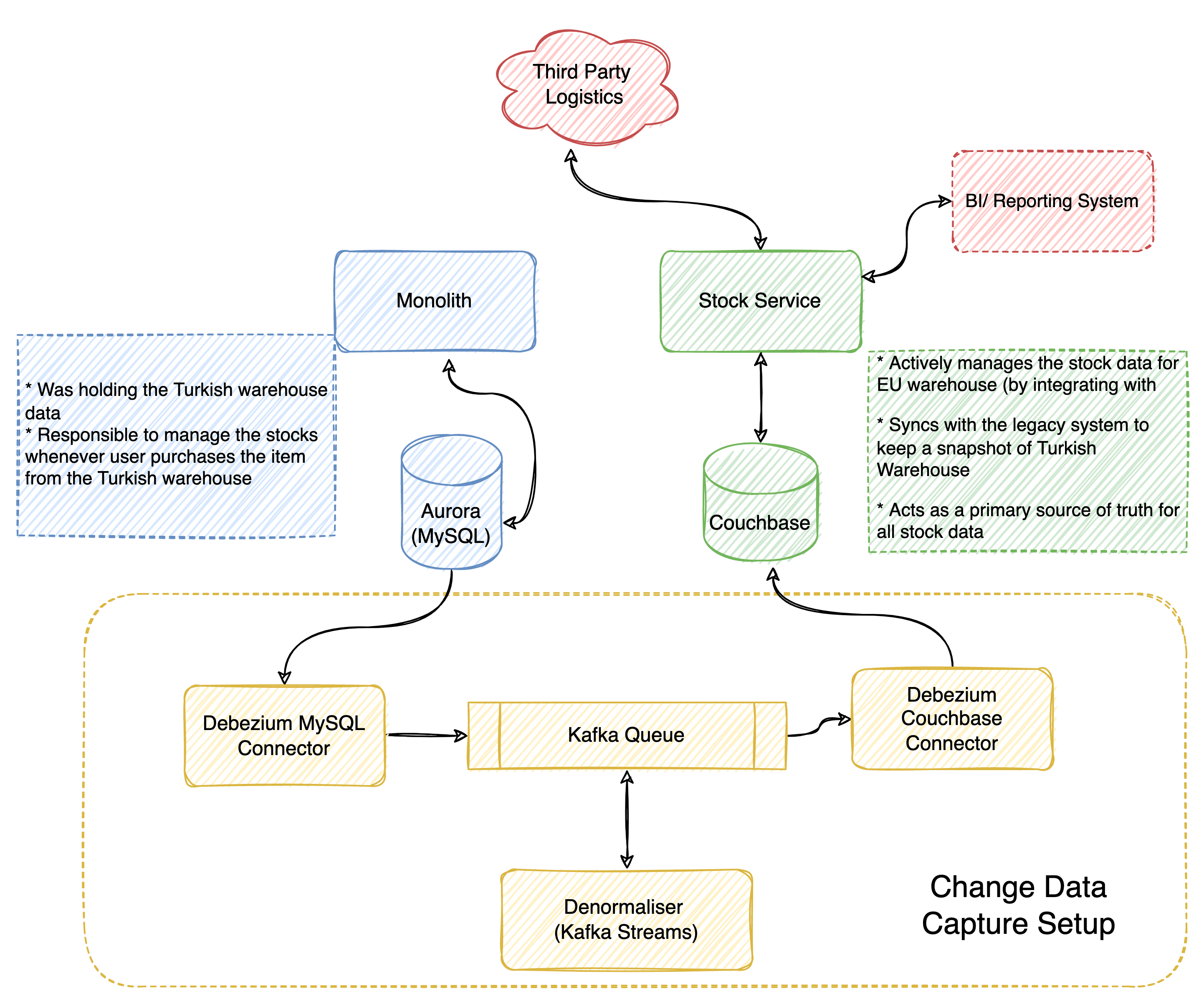
Focussing on the above-mentioned problems, we decided to go with a new Stock service that integrates with the 3PL company and becomes the source of truth for the stock data.
But then the old system is hard to decommission in one go, so the decision was made to keep the Monolith along with the new service. The current workflows involving their current warehouse will be done via the old Monolith and the newer warehouses will start using the new Stock service.
"New stock service will co-exist with the monolith”
Responsibilities of Monolith
The monolith system with the Aurora database had the stock information for their current warehouse and whenever a buyer buys items from the current warehouse, it was handled by this system and stock count reflected in its database.
Responsibilities of New stock service
The new stock service will have couchbase as its database and become the source of truth with respect to all the stock data. The new service will integrate with the new third party logistics (3PL) to manage the stocks in the new warehouse. The new service will have a more granular level of stock information of non-sellable stocks. Any business intelligence reporting tool related to stock will be connected only with the new stock service.
Continuous synchronization of data across databases
This architecture opens up with a problem of continuous synchronization of data between the Aurora database and the Couchbase instance. Since the new service will be the source of truth, and the old one will be decommissioned eventually, it was decided that the synchronization will be one way between Aurora to Couchbase only. This means, the old system will not have stock details for the new warehouse(s).
In order to achieve the data synchronization we opted in for Change data capture pattern. We went with Debezium, to implement the change data capture.
Reasons to go with Debezium
- It’s an open source platform.
- It can be easily used alongside Kafka. We had kafka already in our ecosystem. So the operational overhead was minimum
- There are a wide variety of connectors present for Debezium to connect to source and sink.
We deployed Debezium as Kafka connectors. They generate Kafka events whenever the configured table(s) has any changes. The events were in Apache Avro format and were published to an underlying Kafka instance. We will then have a sink connector which listens to configured events and then posts it back to Couchbase.
Few more things that needed additional care for this change data capture setup.
Transforming normalized table into a denormalized structure
One of the challenges that we need to address while setting up the CDC is the compatibility of source and destination data structures. Aurora being a RDBMS database, the schemas are designed with normalization. In couchbase we had these records in a flat structure. So, multiple records in MySQL will be mapped to a single record in the couchbase.
Let me take an example here. Consider the following tables with the columns.
For any change in the above tables, a CDC event will be created with a content of old data and the modified data. In our couchbase, we had them as documents so we will need to perform a join operation with other tables to create a document.
This join operation was the tricky part to solve. Initially our approach was to use a RDBMS data store, to store the denormalized structure. So every CDC event will update this table and from there another CDC event will help us to update the couchbase instance.
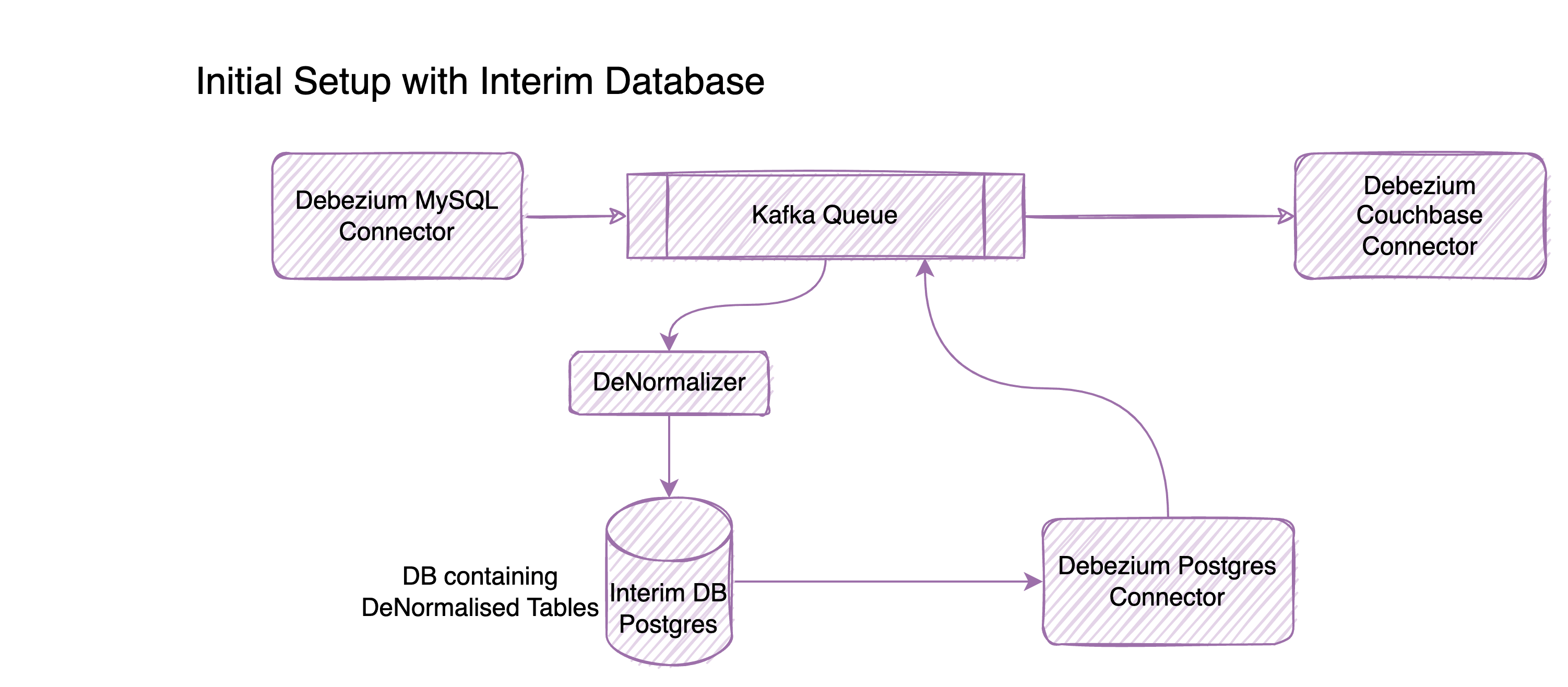
This approach meant an overhead of maintaining an additional database, additional CDC setup.
So, eventually we moved to Kafka streams to solve this problem of joins. We did explore KsqlDB that’s built on Kafka streams but then felt Kafka streams api was sufficient for us to get going. Another alternative we started exploring and eventually dropped due to the learning curve was Apache Flink.
Scale and monitoring aspects
We had ~1.5million records of product data, ~5.3 million records of product variants in the database that need to be synced. There were a few more tables that we needed to consume data from. On an average we were having ~60-75 CDC events per second related to our tables coming into our queue.
Monitoring CDC wasn’t very different from monitoring our kafka queues. For Kafka monitoring, we had this dashboard and extended it. Additionally, to this we had a dashboard to monitor the health of the connectors.
First time load/migration
In our case we used the exact CDC setup for the initial load as well. Debezium sink connectors offered throttling ability, so the spiked load on our couchbase instances were avoided. Though it took time to clear all the messages in our kafka queue, it avoided an additional solution for the first time load.
When to go for CDC?
CDC is a useful technique when doing a microservices migration using a strangler fig pattern. In cases where you need to maintain multiple databases with different structures. In my opinion, Debezium seems to be the best open source solution available right now.
